QK Norm and the Curious Case of Logit Drift
3 October 2024Multimodality has led to some tweaks to the standard Transformer recipe. In this post we will cover QK Normalization (QKNorm), where we apply normalization to the query and key vectors in the attention mechanism. This has become an important step for unified input models where we have tokenized representations of text, images and other modalities present in a single sequence. These types of models are very prone to training instability without appropriate normalization, as the norms of the Q and K vectors can experience exponential growth during training. QKNorm is a necessary (although perhaps not sufficient) step to correct this problem.
What's the problem?
Attention logits are constructed via a scaled dot product in the Transformer attention mechanism:
\[ \text{softmax}(\mathbf{x}) = \text{softmax}(\frac{\mathbf{q} \mathbf{k}^\top}{\sqrt{d_h}}) \]
The softmax is invariant to translation. If we add a constant \(c\) to each element of the input vector \(\mathbf{x}\) then we can see that:
\[ \text{softmax}(\mathbf{x} + c) = \frac{e^{\mathbf{x} + c}}{\sum_j e^{x_j + c}} = \frac{e^c \cdot e^{\mathbf{x}}}{e^c \cdot \sum_j e^{x_j}} = \frac{e^{\mathbf{x}}}{\sum_j e^{x_j}} = \text{softmax}(\mathbf{x}) \]
The invariance property is a potential source of training instability when combined with unnormalized query and key vectors.
To see why, we can write an individual logit of the attention matrix as:
\[ \text{x}_{ij} = \frac{\|\mathbf{q_i}\| \|\mathbf{k_j}\| \cos(\theta_{ij})}{\sqrt{d_h}} \]
Since additions have no impact on the relative magnitudes of the logits, the only way for the model to increase the relative distance between logits is by increasing or decreasing the norms of the \(\mathbf{q}\) and \(\mathbf{k}\) vectors, or adjusting the angle \( \cos\left(\theta_{ij}\right) \). It may be easier for the model to learn to increase the norms, as this requires uniform scaling of weights, as opposed to changing the angles which requires coordinated changes in multiple weight parameters.
However, uncontrolled growth in the norms of these vectors can lead to instabilities in training, as large logits will collapse attention weights to one-hot vectors - "attention entropy collapse" (Dehghani et al 2023, Zhai et al 2023). If the training setup is overly sensitive to some hyperparameters, such as a high learning rate, then norms will be pushed into the exponential region of the softmax. This is the case discussed by Wortsman et al (2023).
Recent empirical evidence suggests that introducing multimodal inputs increases hyperparameter instability, and makes training more prone to norm explosion. We cover the relevant literature in the next section.
What's the evidence?
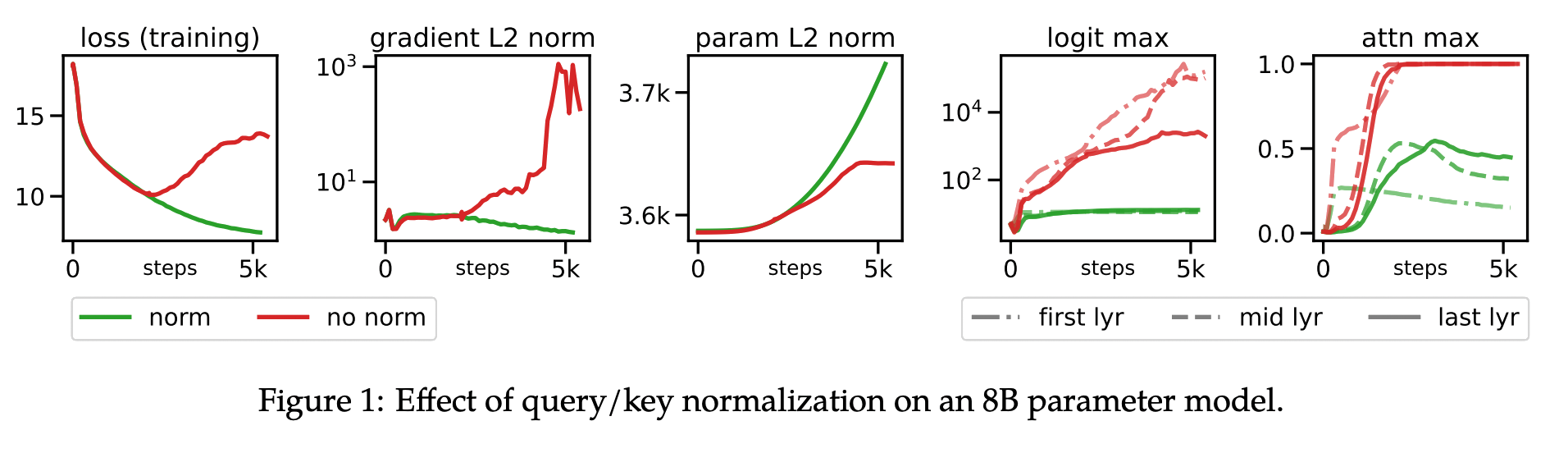
Dehghani et al (2023) observed divergent training with an 8B Vision Transformer. The loss decreased as normal to begin with but then steadily increased after 2,000 steps. Without normalization they found that attention logits grew to over 50,000 in magnitude, resulting in one-hot attention weights post-softmax and subsequently unstable losses and gradients:
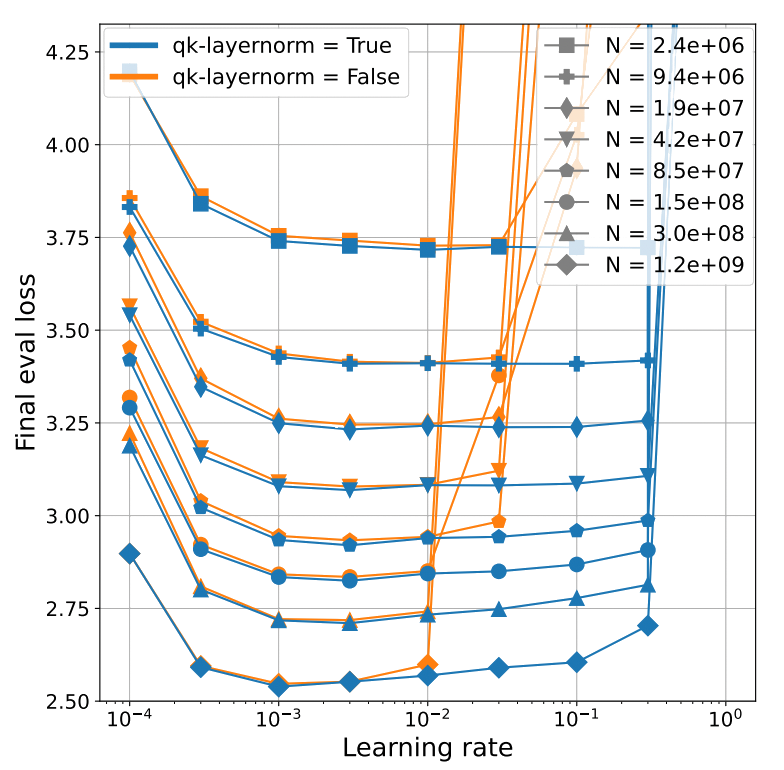
Wortsman et al (2023) found they could obtain attention logit instability with smaller models using higher learning rates. As a solution, they found that QKNorm enabled stable training across three orders of magnitude of learning rate (LR) variation.
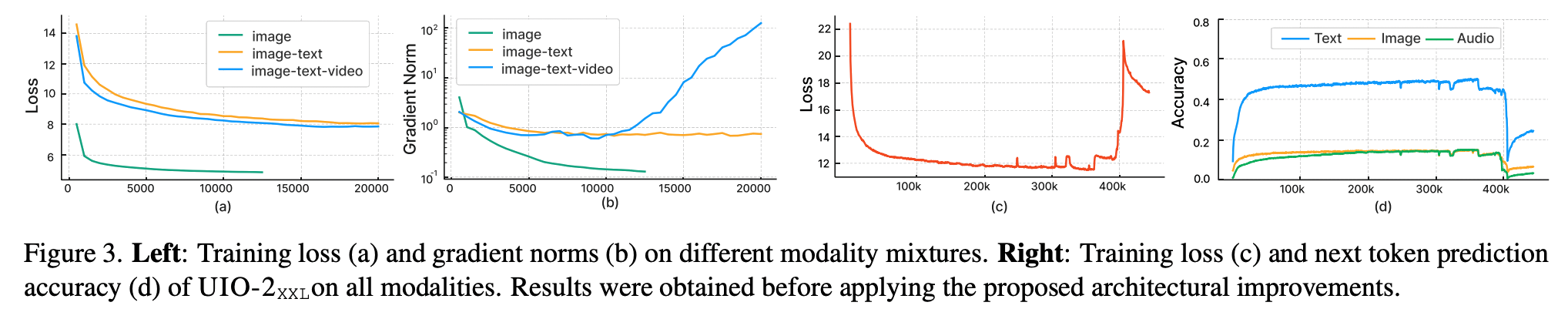
Lu et al (2023) experienced unstable training as they integrated additional modalities into their UnifiedIO architecture. They observed extremely large values in the multi-head attention logits when including image and audio modalities, leading to one-hot attention weights. They used QKNorm to stabilise training.
Chameleon Team (2024) experienced instabilities in the mid-to-late stages of training which they attributed to uncontrolled norm growth. They attribute norm growth to "norm competition" between modalities of differing entropy, which is encouraged by softmax translation invariance. They note this becomes problematic once training reaches outside the effective representation range of bfloat16. They do not observe the same problem for the unimodal text-only setting.
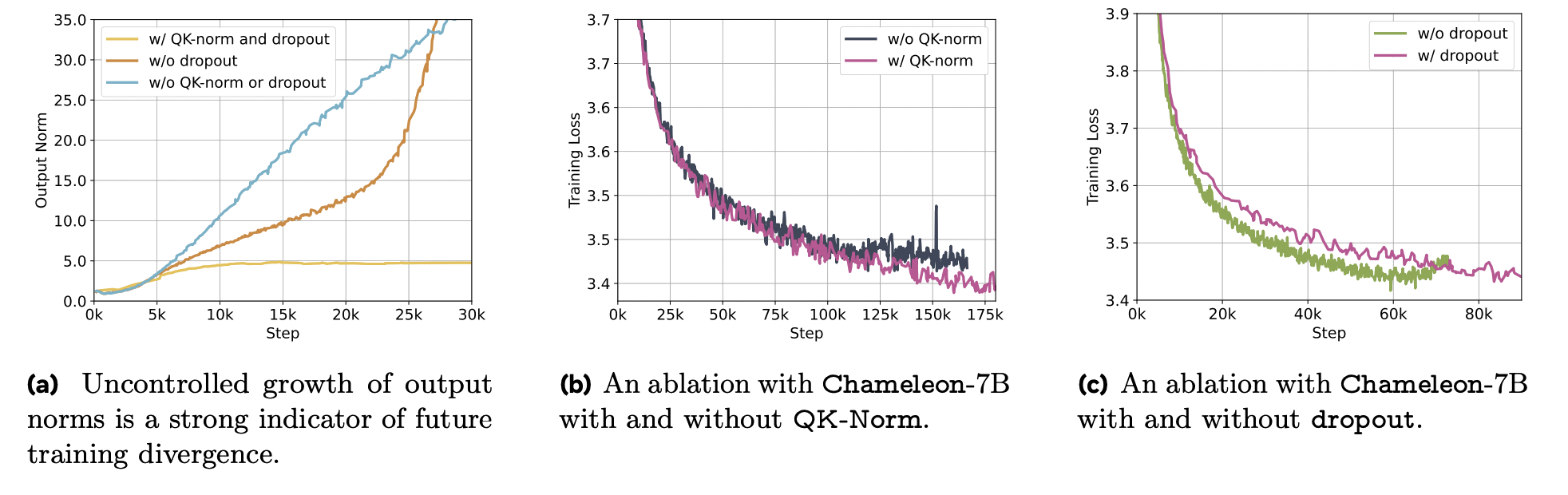
Interestingly, they found that QKNorm alone was not sufficient for stabilising training with the LLaMA architecture. They opt for a Swin Transformer normalization strategy, which normalizes on the outside of the feedforward block (helping bound its norm growth).
Some other recent work includes OLMoE by Muennighoff et al (2024), where they find QKNorm increases training stability (at the cost of 10% throughput). Additionally Ramapuram et al (2024) find QKNorm significantly stabilises performance by making Sigmoid Attention and Softmax Attention less sensitive to learning rate changes.
Why does multimodality lead to norm growth?
Let's look at the \(\mathbf{q}\) and \(\mathbf{k}\) vectors again. Both are \(\left(B, T, C\right)\) size vectors constructed via linear layers (omitting biases):
\[ \mathbf{h_{q,k}} = \mathbf{x} \mathbf{W_{q,k}} \]
where \(x\) is the input embedding. Let's restrict ourselves to looking at query vectors for now for a single batch: \[ \mathbf{q} = \mathbf{x} \mathbf{W_{q}} \] where \(x\) is of size \(\left(T, C\right)\) and \(\mathbf{W_{q}}\) is of size \(\left(C, C\right)\). The norm of an element \(\mathbf{q}_t\) (vector of length \(C\)) is given by:
\[ \|\mathbf{q_t}\| = \|\mathbf{x_t} \mathbf{W_{q}}\| \] where \(\mathbf{x_t}\) is the input embedding of size \(C\) for the \(t\)-th token.
In the unimodal case, the expected norm is constant: \[ E[\|\mathbf{q_t}\|] = \sigma_{x} \cdot \|\mathbf{W_q}\|^2_{F} \] But in the multimodal case, we will have different variances for modalities of differing statistical entropy. For example, images tend to have less structure than text and are more variable (higher entropy), so we would expect the norms to be higher for query vectors from image tokens than word tokens; i.e. \(\sigma_{x_i} > \sigma_{x_j}\) . This means they will dominate the attention mechanism when included alongside text. To compensate the model will increase the norms of the text tokens.
But the softmax is a competitive, zero-sum objective. If we increase the norms of one modality, we increase their attention weight at the expense of other modalities. This dynamic can lead to explosive norm growth if the learning rate is too high. More importantly, the range of learning rates where this dynamic becomes explosive is wider for the unnormalized attention mechanism, as the work by Wortsman et al (2023) showed.
For these reasons, a simple fix is to normalize the query and key vectors before the attention mechanism. A reference PyTorch implementation is provided below.
Implementation
import torch.nn as nn
import torch.nn.functional as F
class SelfAttention(nn.Module):
def __init__(self, dim_size, n_heads, norm=RMSNorm, use_qk_norm=False):
super(SelfAttention, self).__init__()
self.dim_size = dim_size
self.n_heads = n_heads
self.head_dim = dim_size // n_heads
self.qkv_attn = nn.Linear(dim_size, dim_size * 3, bias=False)
self.project = nn.Linear(dim_size, dim_size, bias=False)
self.use_qk_norm = use_qk_norm
if self.use_qk_norm:
self.q_norm = norm(self.head_dim)
self.k_norm = norm(self.head_dim)
def forward(self, x: torch.Tensor):
B, T, C = x.size()
qkv = self.qkv_attn(x)
q, k, v = qkv.split(self.dim_size, dim=2)
q = q.view(B, T, self.n_heads, self.head_dim)
k = k.view(B, T, self.n_heads, self.head_dim)
if self.use_qk_norm:
q = self.q_norm(q)
k = self.k_norm(k)
v = v.view(B, T, self.n_heads, self.head_dim).transpose(1, 2)
y = F.scaled_dot_product_attention(q, k, v, is_causal=True)
y = y.transpose(1, 2).contiguous().view(B, T, C)
y = self.project(y)
return y
Thanks
Thanks to Marcin Kardas and Michiel de Jong for proofreading this post.
If you find my writing interesting, you can follow me at @rosstaylor90 on X.
References
- Query-Key Normalization for Transformers
- Stabilizing Transformer Training by Preventing Attention Entropy Collapse
- Scaling Vision Transformers to 22 Billion Parameters
- Small-scale proxies for large-scale Transformer training instabilities
- Unified-IO 2: Scaling Autoregressive Multimodal Models with Vision, Language, Audio, and Action
- Chameleon: Mixed-Modal Early-Fusion Foundation Models
- OLMoE: Open Mixture-of-Experts Language Models
- Theory, Analysis, and Best Practices for Sigmoid Self-Attention